Uitleg artikel algemene relativiteitstheorie: paragraaf 8
Trefwoorden: algemene relativiteitstheorie, Annalen der Physik, Die Grundlage der allgemeinen Relativitätstheorie/De grondslag van de algemene relativiteitstheorie, Königlich Preussischen Akademie der Wissenschaften/Koninklijke Pruisische Academie der Wetenschappen
Hoofdstuk B:
Wiskundige hulpmiddelen voor de opstelling van algemeen covariante vergelijkingen.
Paragraaf 8:
Enige opmerkingen over de fundamentele tensor gμν.
De tensor g is dermate belangrijk voor de algemene relativiteitstheorie dat Einstein er een hele paragraaf van zijn
artikel aan wijdt.
We zijn deze tensor al een aantal malen tegengekomen en we weten er nu al het een en ander van:
- g staat tegenwoordig te boek als de metrische tensor.
Ondanks dat Einstein hier spreekt over de fundamentele tensor (“Fundamentaltensor”) is deze tensor
niet onder die naam in de geschiedenisboekjes terecht gekomen.
Maar heel soms kom je de aanduiding “fundamentele tensor” toch nog wel ergens tegen.
- g is een tensor van de tweede rang (twee indices: μ en ν).
- g is een covariante tensor (de indices staan onderaan).
- g is een symmetrische tensor (gμν = gνμ).

Vorm wordt weergegeven middels de metrische tensor, een tensor van de tweede rang
Het ruimtetijdinterval ds is invariant, en dus het
kwadraat
van ds ook.
In
paragraaf 4
hebben we uitgebreid gekeken naar het ontstaan van de vergelijking die ds
2 beschrijft:
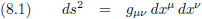 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Waarin dx
μ en dx
ν tweemaal de componenten van willekeurige contravariante
vectoren zijn.
Uit het laatste deel van
paragraaf 7
volgt daaruit eens te meer dat g een covariante symmetrische tensor van de tweede rang is.
Einstein vermeldt er nog expliciet bij dat
dx een contravariante vector is, maar toch gebruikt hij consequent
bij alle
‘
differentiaal-achtige dingen’
lage indices.
En wij dus niet.
In deze paragraaf gaan we heel uitgebreid de metrische tensor g ‘aan de tand voelen’.
De eigenschappen die daarbij aan het licht komen gelden weliswaar voor alle tensoren die net als g van de tweede rang zijn,
maar door de sleutelrol die g vervult binnen de algemene relativiteitstheorie willen we het expliciet juist bij deze tensor zien.
We beginnen eerst met een stukje basiswiskunde:
matrices
en
determinanten.
Over wat een
matrix
is hebben we in
paragraaf 5
al gesproken, maar
determinanten
zijn daarbij nog niet aan de orde geweest.
Stel, we hebben de volgende
matrix M:
De
determinant
van M is gedefinieerd als:
Ik heb hier één keer absoluutstrepen gebruikt om de
determinant
van M aan te geven omdat Einstein dat overal in zijn artikel doet, maar dit is verwarrend (en dus ongewenst).
Absoluutstrepen geven de
absolute waarde
van iets aan, en de
absolute waarde
is de afstand tot nul van dat iets.
Vanaf nu geef ik iedere
determinant
aan met det, zoals tegenwoordig ook gebruikelijk is.
En stelt dat getal, de
determinant,
nog iets voor of kunnen we daar ook iets mee?
Jazeker, de
absolute waarde
van de
determinant
is het
volume van de vectorruimte die door de vectoren in de
matrix
opgespannen wordt.
En zoals ik eerder al zei, we praten over een vectorruimte ongeacht het aantal dimensies van die ruimte.
De
matrix
M zoals hierboven beschreven zou bijvoorbeeld kunnen bestaan uit twee vectoren V
1 (a, c) en V
2 (b, d).
Deze twee vectoren vormen twee zijden van een vierhoek: een
parallellogram.
En ofschoon dit parallellogram zo plat is als een dubbeltje spreken we toch van een vectorruimte.
Het volume van deze vectorruimte (lees: de oppervlakte van het parallellogram) is gelijk aan | det (M) |.
Altijd?
Ja, altijd!
Laten we eens kijken naar een 3 × 3
matrix.
De
matrix
P zoals hierboven beschreven zou kunnen bestaan uit drie vectoren V
1 (a, d, g),
V
2 (b, e, h) en V
3 (c, f, i).
Deze drie vectoren vormen drie zijden van een ‘scheef blok’: een
parallellepipedum.
Ook hier geldt: het volume van deze vectorruimte (lees: het volume van het parallellepipedum) is gelijk aan | det (P) |.
Maar hoe bereken je dan de
determinant
van P?
Dat doen we door in de
matrix
P op zoek te gaan naar
ondermatrices, en daarbij stellen we ons voor dat de
matrix
op de plaats van de haken aan elkaar gelijmd is zodat je een cilindervorm krijgt met de letters a t/m i aan de buitenkant
van de cilinder.
- Vanuit a bezien is het blok (e, f, h, i) een ondermatrix met als
onderdeterminant
(ei − fh).
- Vanuit b bezien is het blok (f, d, i, g) een ondermatrix met als
onderdeterminant
(fg − di).
- Vanuit c bezien is het blok (d, e, g, h) een ondermatrix met als
onderdeterminant
(dh − eg).
In plaats van de term
onderdeterminant
zie je tegenwoordig ook wel de term
minor, maar volgens mij is dit overgenomen uit het Engels zonder dat men
nog beseft dat het Engels is (zoals men bij trottoir niet meer beseft dat het Frans is en dat het gewoon stoep heet).
Vanaf nu duid ik de
onderdeterminant
aan met odet.
De totale
determinant
van P wordt dan:
Ondermatrices en
onderdeterminanten
kun je bepalen vanuit iedere positie binnen de
matrix.
En daarvoor is het eigenlijk het handigst om de
matrix
te visualiseren alsof die helemaal omringd is door soortgelijke
matrices.
Stel dat ik ondermatrices wil bepalen vanuit de rij d e f, dan hoef ik alleen maar te kijken welke vier
elementen
zich rechtsonder mijn kijkpositie bevinden.
- Vanuit d bezien is het blok h i, b c een ondermatrix met als
onderdeterminant
(ch − bi).
- Vanuit e bezien is het blok i g, c a een ondermatrix met als
onderdeterminant
(ai − cg).
- Vanuit f bezien is het blok g h, a b een ondermatrix met als
onderdeterminant
(bg − ah).
De totale
determinant
wordt dan:
En hier komt (uiteraard) hetzelfde uit als toen ik ‘keek’ vanuit de rij a b c.
Het maakt helemaal niets uit vanuit welke rij
of kolom ik ondermatrices ga bepalen, altijd weer kom
ik voor de totale
determinant
op hetzelfde resultaat uit.
Een andere benadering om een
determinant
samen te stellen uit
onderdeterminanten
is als volgt.
Stel dat ik de
onderdeterminant
van b wil bepalen dan sloop ik de rij en de kolom waar b in voorkomt (dus de eerste
rij en de tweede kolom) uit de
matrix.
Wat er dan overblijft is het blok d f, g i.
De
determinant
hiervan is di − fg.
Vervolgens tel ik het rijnummer en het kolomnummer op van het
element
waarvan ik de ondermatrix bepaal, indien deze som even is dan krijgt de
onderdeterminant
een plusteken en indien de som oneven is een minteken.
Het rijnummer van het
element
b is 1 en het kolomnummer is 2.
De som hiervan is 1 + 2 = 3, dit is oneven dus krijgt de
onderdeterminant
een minteken mee.
Dit is wat minder inzichtelijk maar je kunt het altijd blind toepassen.
En van hieruit gaan we nog een stap verder door een 4 × 4
matrix
onder de loep te nemen, en wel met de methode die ik zojuist heb beschreven.
We zien bijvoorbeeld dat de ondermatrix van a gevormd wordt door het blok f g h, j k l, n o p.
De
onderdeterminant
van a is dan f(kp − lo) + g(ln − jp) + h(jo − kn).
Het rijnummer van a is 1 en het kolomnummer is ook 1.
De som hiervan is 1 + 1 = 2, dit is even dus krijgt de
onderdeterminant
een plusteken mee.
Dit gaan we doen voor alle
elementen
van de
matrix
Q.
De totale
determinant
van de
matrix
Q wordt dan:
Nu gaan we een nieuwe
matrix
bouwen.
Deze
matrix
noemen we R en elk
element
van de
matrix
R wordt gevormd door van elk overeenkomstige
elementen
van de
matrix
Q de
onderdeterminant
te nemen en te delen door de
determinant
van Q.
En met elk ‘overeenkomstig
element’
bedoel ik het
element
van de
matrix
R die op dezelfde positie staat als een
element
in de
matrix
Q.
Er geldt dus:
Het
element
a van de
matrix
Q heeft als
onderdeterminant
+(f(kp − lo) + g(ln − jp) + h(jo − kn)) en het linksboven
element
van de
matrix
R wordt dus
+(f(kp − lo) + g(ln − jp) + h(jo − kn))/det (Q).
Om de vergelijkingen niet te lang te maken schrijf ik det (Q) niet volledig uit in
elementen.
Hoe zien dan alle
elementen
van de
matrix
R eruit?
Voor de overzichtelijkheid zet ik ze onder elkaar in een tabel.
| Element Q |
Element R
(inclusief het bijbehorende teken!) |
| a |
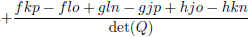 |
| b |
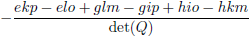 |
| c |
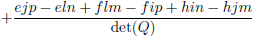 |
| d |
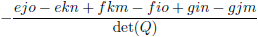 |
| e |
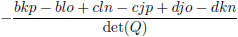 |
| f |
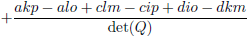 |
| g |
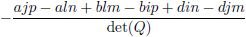 |
| h |
 |
| i |
 |
| j |
 |
| k |
 |
| l |
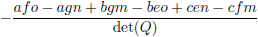 |
| m |
 |
| n |
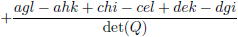 |
| o |
 |
| p |
 |
| Tabel 8.2 |
Om de chaos helemaal compleet te maken ga ik deze twee
matrices,
Q en R, met elkaar vermenigvuldigen.
De
matrix
die dan ontstaat noemen we S.
Matrices
vermenigvuldigen doe je door de
rij
elementen
van de ene
matrix
met de
kolom
elementen
van de andere
matrix
te vermenigvuldigen.
Het eerste
element
van de
matrix
S wordt dan:
Stel nou dat de
matrix Q
symmetrisch
is (net als voor tensoren geldt dan dat Q
rk = Q
kr), dan geldt:
De
determinant
van Q wordt dan:
En het
element
s
11 wordt dan:
Die zag je niet aankomen hè?
Waarschijnlijk zat je te denken waar deze gigantische puinhoop toe moest leiden (wat ik me helemaal kan voorstellen ☺),
en dan staat daar ineens 1!
Kijk, nu wordt het ineens heel interessant.
Daarom gaan we snel het volgende
element
van de
matrix
S bepalen:
En hier komt nul uit!
De overige
elementen
mag je zelf narekenen, maar uiteindelijk gaat de
eenheidsmatrix
ontstaan: een
hoofddiagonaal
gevuld met enen en voor de rest allemaal nullen.
En dit hebben we in
paragraaf 5
ook al gezien toen we tot de volgende vergelijkingen kwamen:
En omdat ik hier uitgegaan ben van een symmetrische
matrix
(Q
rk = Q
kr) is de
matrix
Q de
getransponeerde
versie van zichzelf.
Dus stel dat Q een covariante tensor is dan heb ik op deze manier zijn contravariante tegenhanger gemaakt
(en andersom geldt natuurlijk precies hetzelfde).
Haal ik nou geen tensoren en
matrices
door elkaar?
Nee, voor dit soort rekenkundige bewerkingen zijn tensoren en
matrices
aan elkaar gelijk, een tensor kun je zien als een
matrix,
maar een
matrix
niet per definitie als een tensor.
Een
matrix
is een rechthoek gevuld met getallen die in rijen en kolommen opgesteld staan.
Niets meer en niets minder.
Een tensor
is iets en een tensor
doet iets, een tensor is onafhankelijk van coördinatenstelsels
en de componenten van een tensor transformeren volgens de transformatievergelijkingen.
- de tensor gμν is iets, het is de metrische beschrijving van de
n-dimensionale ruimte (in dit geval de 4-dimensionale ruimtetijd),
- de tensor gμν doet iets, als ik een vector V vermenigvuldig
met een scalar (getal) a dan krijg ik een vector die in de zelfde richting wijst als V, als ik V
vermenigvuldig met de vector W via het
uitwendig product
V × W dan ontstaat een vector die
loodrecht op V en W staat, maar als ik de bewerking gμν Vν
uitvoer dan ontstaat een vector die iedere vrijheidsgraad heeft om waar dan ook heen te wijzen: de tensor
gμν is een soort vector-bijbuig-machientje,
- de tensor gμν is onafhankelijk van coördinatenstelsels,
- de componenten van de tensor gμν transformeren volgens
∂xν/∂xσ'.
Wanneer ik tig keer met een dobbelsteen gooi en het aantal ogen dat ik iedere keer gooi schrijf ik netjes op dan
ontstaat een
matrix,
maar volgens bovenstaande punten is dat in de verste verte geen tensor.
Aan de andere kant gelden alle eigenschappen van
matrices
wel voor tensoren.
Een tensor is
altijd een
matrix,
een
matrix
zou een tensor
kunnen zijn.
Hierboven heb ik laten zien dat wanneer ik van een symmetrische
matrix
Q van ieder
element
de
onderdeterminant
neem en die vervolgens deel door de
determinant
van Q dan kan ik daaruit een nieuwe
matrix
R vormen.
Door die twee
matrices
met elkaar te vermenigvuldigen ontstaat de
eenheidsmatrix
I.
Met andere woorden, de
matrices
Q en R zijn de inverse
matrices
van elkaar (Q is de inverse
matrix
van R en R is de inverse
matrix
van Q).
Vergelijking (8.16) kan ik natuurlijk ook opschrijven voor de metrische tensor g, maar dan heb ik nog een ‘ding’ nodig
met indices die ik kan aanduiden als een ‘eenheidstensor’.
Dit ‘ding’ heet de Kronecker-delta: δ (genoemd naar Leopold Kronecker).
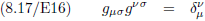 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Waarbij geldt:
Nu moet ik wel even goed bedenken dat ik in de beide bovenstaande tabellen de plussen en minnen van de
onderdeterminanten
van Q respectievelijk de
elementen
van R al meegenomen had.
Volgend uit al het voorgaande kan ik nu opschrijven:
Wanneer ik de inverse bepaal van een gewone
matrix
dan doe ik dat als volgt:
Dit ziet er iets anders uit dan de vergelijkingen (17a) en (17b), omdat de indices van plaats wisselen.
Voor de metrische tensor maakt dat echter niet uit, omdat die tensor symmetrisch is.
En ik heb hier telkens gesproken over de metrische tensor, maar dit hele verhaal geldt uiteraard voor iedere
symmetrische tensor van de tweede rang.
Laat ik vergelijking (8.1) weer even terug in herinnering roepen:
Oorspronkelijke vergelijking uit het artikel van Einstein:
De indices μ en ν staan allebei een keer boven en onder, dus daar moet over gesommeerd worden:
Maar stel dat ik vergelijking (8.1) nou een beetje verbouw en daar de Kronecker-delta bij in zet:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Nu heb ik drie indices waarover ik moet sommeren: μ, ν en σ:
En dan hebben we weer zo’n kolossale puinhoop die je inmiddels wel van mij gewend bent.
Maar, iedere term waar een δ in staat met indices die
niet aan elkaar gelijk zijn kan ik eruit gooien,
want in die gevallen is δ gelijk aan nul.
En alle δ’s die er nu nog in staan zijn gelijk aan 1, dus wat blijft er dan over:
En zo zijn we weer terug bij hetzelfde resultaat als vergelijking (8.18).
En dat is ook wel logisch, want δ is het tensor equivalent van de
eenheidsmatrix
I, dus vermenigvuldigen met δ maakt niets uit (en dat heb ik hierboven laten zien).
Vergelijking (8.1) en vergelijking (8.19) zijn dus gelijkwaardig.
En volgens vergelijking (8.17/E16) kan ik δ in vergelijking (8.19) vervangen als volgt:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Verder weten we inmiddels ook, zie bijvoorbeeld de uitleg van
paragraaf 7,
wat de vermenigvuldiging van een covariante tensor met een contravariante vector doet:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

En dit geldt voor iedere vector
dx.
Dus we kunnen in vergelijking (8.23) de vermenigvuldiging van de covariante tensor g met de vector
dx vervangen
door de vector
dζ.
En dat zelfs tweemaal in vergelijking (8.23) en levert dan het volgende op:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
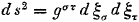
Omdat ds
2 een scalar is (dus invariant), en omdat we hier tweemaal dezelfde vector
dζ
hebben staan, en omdat g
στ symmetrisch is (g
στ = g
τσ)
volgt hieruit dat g
στ een contravariante tensor is.
We doen hier eigenlijk hetzelfde als aan het einde van de uitleg van
paragraaf 7.
En door nogmaals naar vergelijking (8.17/E16) te kijken kunnen we ook nog de conclusie trekken dat
δ
μν een tensor is.
Einstein merkt nog op dat we δ
μν kunnen duiden als de
gemengde fundamentele tensor (“gemischten Fundamentaltensor”), maar tegenwoordig kent iedereen
dit als de Kronecker-delta.
Wat geldt er verder nog voor
matrices
en
determinanten?
De
determinant
van het product van twee
vierkante matrices
is gelijk aan het product van de
determinanten
van die
matrices.
Voor twee
vierkante matrices
A en B ziet dat er in formulevorm zo uit:
En Einstein gebruikt dit voor de volgende combinatie:
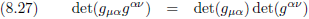 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

En uit vergelijking (8.17) volgt:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

En dat is hetgeen ik hiervoor met de
matrices
Q, R en S helemaal uitgewerkt heb.
Door de vergelijkingen (8.27) en (8.28) te combineren kom ik tot het volgende:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

De
determinant
van g
μν geven we aan met het getal g:
Na transformatie wordt dit:
In
paragraaf 6
zijn we tot deze vergelijking gekomen als transformatievergelijking voor een covariante tensor van de tweede rang:
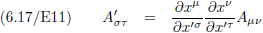 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
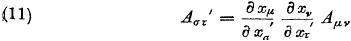
En die gaan we combineren met vergelijking (8.31):
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

En volgens vergelijking (8.26) kunnen we dit ‘uit elkaar trekken’ tot:
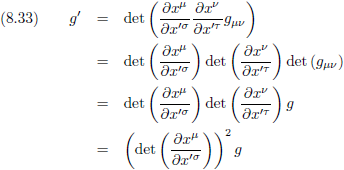 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
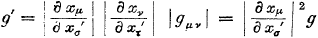
Oftewel:
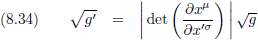 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Nu komt er even iets problematisch, want Einstein komt met de volgende vergelijking als beschrijving van een
volume-element van de vierdimensionale ruimtetijd:
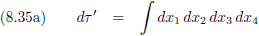 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
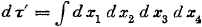
Hij praat dus over een
volume-element, met andere woorden, hij bedoelt een
klein stukje volume ruimtetijd.
Aan de linkerkant van de vergelijking staat ook een d om te benadrukken dat het over een klein stukje gaat.
Maar wat doet dat
integraalteken
dan in deze vergelijking?
Dat
integraalteken
hoort hier simpelweg niet thuis.
Het volgende probleem is dat aanhalingsteken (') bij de τ, want dat impliceert dat links iets staat dat de getransformeerde
versie is van wat aan de rechterkant staat.
Ook dat is niet juist.
Dat aanhalingsteken hoort hier ook simpelweg niet thuis.
En dan wil ik ook nog opmerken dat de letter τ onhandig gekozen is, want τ is de Griekse letter t en wordt
doorgaans in verband met tijd gebruikt.
Dus een andere letter was hier beter op zijn plaats geweest, maar dit laat ik maar zo.
In 1921 heeft Einstein colleges gegeven aan de universiteit van Princeton en op basis daarvan is in 1922 een boek
verschenen getiteld “The meaning of relativity”.
In dit boek zijn inderdaad het aanhalingsteken en het
integraalteken
weggelaten en voor de letter τ is een andere letter gekozen.
Einstein was op dit punt er gewoon even niet bij met zijn gedachten, dat kan gebeuren.
Ik introduceer hier de Jacobiaan, genoemd naar de Duitse wiskundige Carl Jacobi.
Dit is een
matrix,
die aangegeven wordt met de hoofdletter J, waarvan de
elementen
bestaan uit alle
afgeleiden
van een functie van iedere uitgangsvariabele naar iedere ingangsvariabele.
Stel, ik heb de volgende functie:
Ik heb hier één ingangsvariabele, x, en één uitgangsvariabele, y.
De Jacobiaan is in dit geval een 1 × 1
matrix
met één
element,
namelijk:
De Jacobiaan ziet er dan als volgt uit:
Stel, ik heb de volgende functie:
Ik heb nu drie ingangsvariabelen, x, z en α, en nog steeds één uitgangsvariabele, y.
De Jacobiaan is in dit geval een 3 × 1
matrix
met drie
elementen,
namelijk:
De Jacobiaan ziet er dan als volgt uit:
Aan het einde van
paragraaf 5
hebben we al kennis gemaakt met de
gradiënt
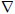
.
Merk op dat in dit geval geldt:
Stel, ik heb de volgende functie:
Ik heb hier nog steeds drie ingangsvariabelen, x, z en α, maar nu twee uitgangsvariabelen, y
1 en y
2.
De Jacobiaan is in dit geval een 3 × 2
matrix
met zes
elementen,
namelijk:
De Jacobiaan ziet er dan als volgt uit:
Ik kan x aangeven als x
1, z als x
2 en α als x
3.
Of in zijn algemeenheid de ingangsvariabelen als x
r en de uitgangsvariabelen als y
k.
De Jacobiaan ziet er dan uit als volgt:
Iedere kolom van de Jacobiaan bestaat dus uit de componenten van een
gradiëntvector
en indien de Jacobiaan uit één kolom bestaat (k = 1) dan geldt (zoals we in het voorbeeld hierboven al zagen):
En in zijn algemeenheid geldt dus:
Waar de
gradiënt
een veralgemenisering is van de
afgeleide
van een functie met één ingangsvariabele naar een functie met meerdere ingangsvariabelen, daar is de Jacobiaan
de veralgemenisering van een functie met één uitgangsvariabele naar functies met meerdere uitgangsvariabelen.
De
afgeleide
y is een vector met als componenten ∂y/∂x
1,
∂y/∂x
2, ∂y/∂x
3, enzovoort.
De
afgeleide
J
f is een
matrix
met als kolommen
y
1,
y
2,
y
3,
enzovoort.
Wanneer ik een ‘gewone’ kromme beschouw, een lijn dus, dan zegt de
afgeleide
dy/dx mij voor ieder punt van die kromme ‘waar het heen gaat’.
Stijgt de kromme of daalt de kromme?
En in welke mate?
Voor ieder punt van de kromme verschaft de
afgeleide
dy/dx mij die informatie.
De
afgeleide
dy/dx geeft mij informatie over één dimensie: omhoog of omlaag.
Middels de
afgeleide
dy/dx kan ik een
raaklijn beschrijven aan de kromme.
Als ik terugdenk aan het voorbeeld aan het einde van
paragraaf 5
met het weiland en de grassprietjes, waar ik
een scalarveld verkregen had door van ieder grassprietje de hoogte op te meten, dan zegt de
afgeleide
, de
gradiëntvector,
mij voor ieder punt ‘waar het heen gaat’.
Stijgt het scalarveld of daalt het scalarveld (langere of kortere grassprietjes)?
En in welke mate?
En in welke richting (want we hebben het over een vector)?
Voor ieder punt van het scalarveld verschaft de
gradiëntvector
mij die informatie.
De
gradiëntvector
geeft mij informatie over alle dimensies samen: omhoog of omlaag.
En de componenten van de
gradiëntvector
zijn die informatie per dimensie.
Middels de
afgeleide
kan ik een raakvector (de
gradiënt)
en een raakvlak (met als richtingsvectoren de componenten van )
beschrijven aan het scalarveld.
Wanneer ik in de ruimte waar ik nu zit op ieder punt de zwaartekracht meet dan ontstaat een
vectorveld,
want voor ieder punt van de ruimte heb ik dan een getal die de intensiteit van het zwaartekrachtveld weergeeft
plus een
richting van het veld.
De Jacobiaan is de
afgeleide
van dit vectorveld en iedere kolom is een vector
die mij per dimensie zegt ‘waar het heen gaat’.
Neemt de intensiteit van het vectorveld toe of neemt de intensiteit van het vectorveld af (meer of minder
zwaartekracht)?
En in welke mate?
Voor ieder punt van het vectorveld verschaft de
afgeleide
J mij die informatie.
De
afgeleide
J geeft mij informatie over alle dimensies samen: meer of minder zwaartekracht.
En de kolommen van J zijn die informatie per dimensie.
Middels de
afgeleide
J kan ik een
raakruimte beschrijven aan het vectorveld.
De Jacobiaan heeft heel veel weg van de contravariante
transformatiematrix
maar is toch echt iets anders.
De Jacobiaan gaat over
afgeleiden,
over raaklijnen, over raakvlakken, over raakruimtes, over richtingen, en inderdaad over
gradiënten.
Terwijl de
transformatiematrix,
het woord zegt het al, puur bestaat om coördinatentransformaties te beschrijven.
De
transformatiematrix
is bovendien altijd
vierkant
(evenveel rijen als kolommen) en dat hoeft de Jacobiaan absoluut niet te zijn.
Maar dit laatste is wel een belangrijke essentie, want de
afgeleide
∂y/∂x toont hoe y gerelateerd is
aan x en de transformatie ∂x'/∂x toont hoe x' is gerelateerd aan x.
En zoals we aan het begin van deze paragraaf hebben geleerd is de
determinant
van een
matrix
het volume van de vectorruimte die door de vectoren in de
matrix
opgespannen wordt.
De Jacobiaan J is een
matrix
die gevuld is met
gradiëntvectoren
.
Dus de
determinant
van J is het volume van de ruimte die de
gradiëntvectoren
opspannen.
Stel dat ik een eenheidsvolume dV heb (een volume met inhoud één) dan heeft dit volume na transformatie een
inhoud dV'.
En dit getransformeerde volume wordt opgespannen door de
gradiëntvectoren.
Met andere woorden:
En wanneer we dit toepassen op vergelijking (8.35c):
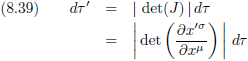 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
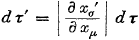
Nu gaan we vergelijking (8.34) vermenigvuldigen met vergelijking (8.39) op de volgende manier: het linkerlid met het linkerlid
en het rechterlid met het rechterlid:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Dit is een hele fijne uitkomst, want dit betekent dat √g dτ invariant is.
Na een transformatie naar een ander coördinatenstelsel blijft de grootheid √g dτ onveranderd.
Nu komt Einstein op het punt om nog even een belangrijk ‘vlekje’ aan de orde te stellen.
In
paragraaf 4
heb ik het interval s
2 op twee manieren bekeken:
In principe is voor beide evenveel te zeggen, maar tot nu toe gingen we stilzwijgend uit van vergelijking (4.7).
Dit heeft echter als vervelende bijkomstigheid dat s
2 dan altijd negatief is en het interval s dus
altijd
imaginair
is.
Daarom gaan we nu over van √g op √(−g).
Dan doen we echt niets illegaals maar we gooien wel een heleboel abstractheid overboord
(een
imaginair
interval, bah!).
Dus vergelijking (8.40) gaat over in:
En Einstein benadrukt het nog maar weer eens, het volume-element √(−g) dτ is een stukje ruimtetijd dat
gewoon met meetlatten en klokken is te meten.
Oftewel, dan blijven we dicht bij de werkelijkheid (heel belangrijk!).
En dan gaat Einstein ook gelijk door naar het volgende ‘vlekje’.
In het oneindig kleine, het infinitesimaal kleine, is altijd de speciale relativiteitstheorie van toepassing want
daar zijn geen versnellingen of zwaartekrachtvelden merkbaar.
Let wel, er kan best een zwaartekrachtveld (of versnelling)
zijn, maar niet
merkbaar.
Stel je voor dat je je in een sterk zwaartekrachtveld bevindt, bijvoorbeeld vlakbij een
zwart gat,
dan zul je merken dat het
verschil in
zwaartekracht tussen je hoofd en je voeten er toe leidt dat het voelt alsof je lichaam uit elkaar getrokken wordt.
Oftewel, het is de
gradiënt
van het veld die zich doet gelden, maar in het oneindig kleine wordt die
gradiënt
nul en kun je dus met de
speciale relativiteitstheorie werken als limietgeval van de algemene relativiteitstheorie (zie ook het verhaal over
getijdenkrachten
in de uitleg van
paragraaf 2).
Zoals we in
paragraaf 4
al zagen praten we in het infinitesimaal kleine dan ook over het interval ds:
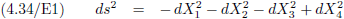 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
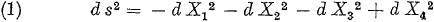
Vervolgens introduceert Einstein een hierbij behorend “
natuurlijk volume-element”
(“natürliche Volumelement”) dτ
0:
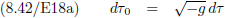 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Indien g nu ergens gelijk aan nul zou worden dan hebben we een groot probleem, want dan verdwijnt er
zomaar een stuk ruimtetijd.
Dit gebeurt dan weliswaar alleen in onze wiskundige aanpak, maar dat maakt het niet minder onacceptabel.
Oftewel, g mag
nooit nul worden want dan zijn we heel erg verkeerd bezig.
In de werkelijkheid zal er natuurlijk ook nooit ‘iets’ verdwijnen omdat we overgaan naar een ander
coördinatenstelsel, dus dan willen we dat in onze wiskundige hocus-pocus ook niet.
Conclusie: g mag nooit nul worden.
En dat brengt Einstein ertoe de volgende stap te maken.
Hij stelt dat g nooit nul mag zijn, en g is sowieso altijd negatief, en g is nooit min-oneindig (want
dan zijn we aan de andere kant van het spectrum weer de werkelijkheid kwijt), dus g is altijd een
‘normaal’ negatief getal.
Waarom stellen we niet op voorhand dat g altijd −1 moet zijn?
Dan wordt het leven veel simpeler en gaat vergelijking (8.41) over in:
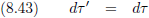 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Oftewel, volgens vergelijking (8.39):
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Ja, maar mag dat zomaar?
Introduceren we hiermee niet een enorme beperking op waar we mee bezig zijn?
Zijn we dan nog wel bezig een algemene relativiteitstheorie op te bouwen?
Dit zijn allemaal logische vragen die Einstein voorzag en gelijk in zijn artikel pareert.
In
paragraaf 3
zijn we tot het volgende gekomen:
- De algemene natuurwetten (alle natuurkundewetten) moeten in vergelijkingen worden uitgedrukt die
in alle coördinatenstelsels geldig zijn.
Dat een vergelijking bij een coördinatentransformatie naar een ander coördinatenstelsel geldig blijft, heeft de naam
covariantie.
Met andere woorden: de natuurwetten dienen algemeen covariant te zijn.
Wat we zoeken zijn dus de algemeen covariante natuurwetten.
We zoeken
niet de natuurwetten die transformeren naar een ander coördinatenstelsel onder de voorwaarde dat de
determinant
gelijk aan één is.
Nee, we zoeken eerst de algemeen covariante natuurwetten, en
daarna maken we ons het leven eenvoudiger door
uit te gaan van een
determinant
die gelijk aan één is.
Het laatste deel van paragraaf 8 gebruikt Einstein om nog een beetje te ‘spelen’ met de metrische tensor.
Door tensoren met g
μν of g
μν te vermenigvuldigen (inwendig
en/of uitwendig, zie uitleg
paragraaf 7)
ontstaan (uiteraard) nieuwe tensoren.
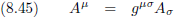 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Op deze manier hebben we van de covariante tensor A
σ zijn contravariante tegenhanger A
μ
gemaakt.
Of plat gezegd: we hebben een index
omhoog gebracht.
We kunnen natuurlijk ook het omgekeerde doen, en dat heet een index
omlaag brengen.
We kunnen ook scalars vormen, en na alles wat we inmiddels al achter ons hebben liggen is dit inmiddels een open deur:
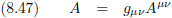 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
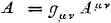
We hebben net indices omhoog gebracht en omlaag gebracht voor een tensor van de eerste rang, een vector, maar er is
helemaal niets op tegen om dit op uitgebreidere schaal te doen:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

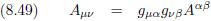 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

Vervolgens komt Einstein nog met deze twee:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
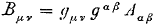
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:

En eerlijk gezegd zie ik hier de toegevoegde waarde niet van in.
Einstein zegt hierover “dat de tensor B de bij A behorende gereduceerde tensor is” (“den zu A gehörigen reduzierten Tensor”).
Ik geef eerlijk toe dat ik niet weet wat Einstein hier voor ogen had.
De vergelijkingen kloppen wel, maar voegen in mijn beleving niets toe.
In zijn laatste vergelijking van deze paragraaf doet hij iets soortgelijks:
 Oorspronkelijke vergelijking uit het artikel van Einstein:
Oorspronkelijke vergelijking uit het artikel van Einstein:
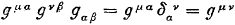
De laatste vergelijkingen van deze paragraaf zijn buitengewoon voor de hand liggend, maar dat zal Einstein zich ook gerealiseerd hebben.
Of misschien toch even niet?

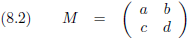

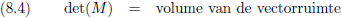
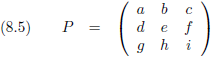
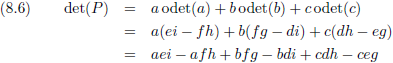
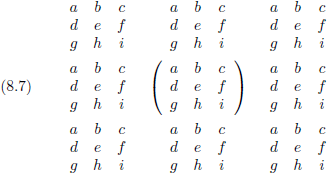
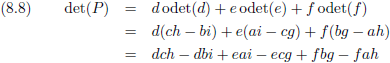
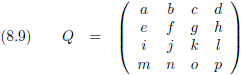
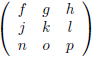

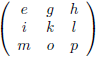

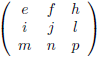

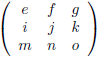
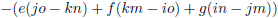


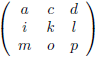
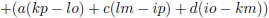
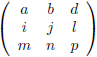

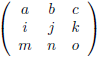
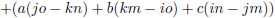
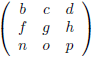
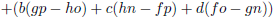
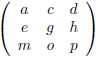
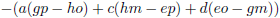

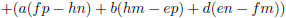




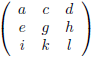
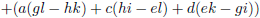

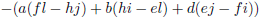
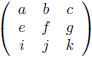

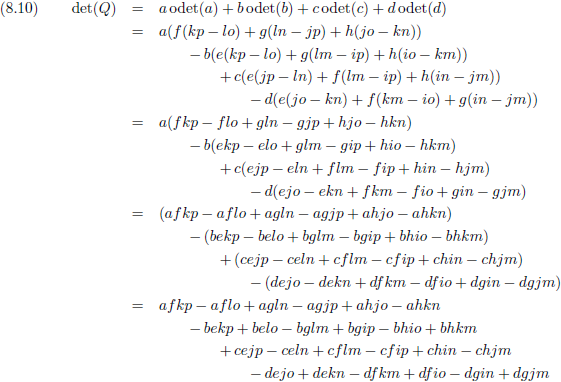
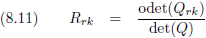
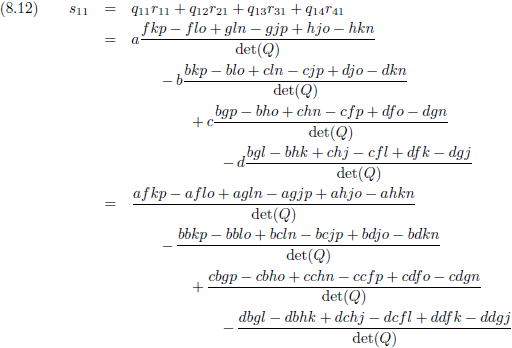

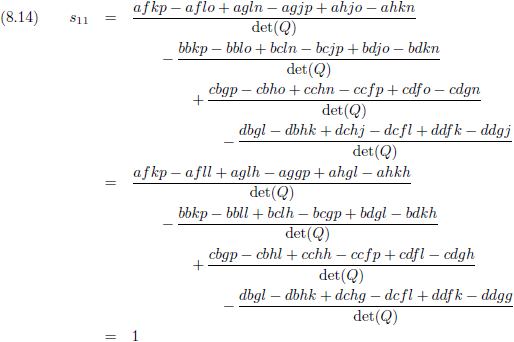

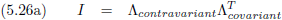
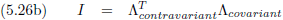
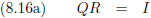


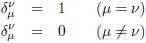

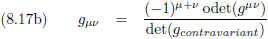
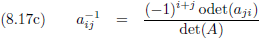



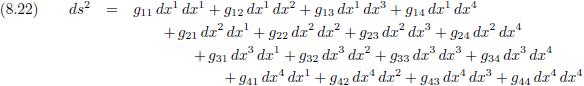


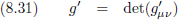

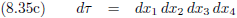

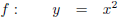
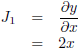
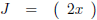

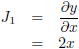
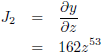
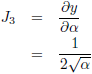



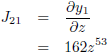
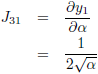
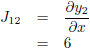
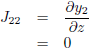


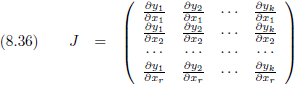
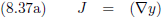



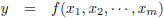
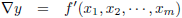
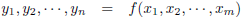
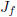

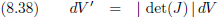
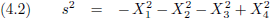
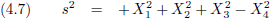

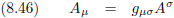
 Naar de uitleg van de volgende paragraaf: paragraaf 9
Naar de uitleg van de volgende paragraaf: paragraaf 9 Naar de uitleg van de vorige paragraaf: paragraaf 7
Naar de uitleg van de vorige paragraaf: paragraaf 7 Overzichtspagina van het artikel
Overzichtspagina van het artikel Overzichtspagina relativiteitstheorie
Overzichtspagina relativiteitstheorie De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integralen van
De integralen van De integralen van
De integralen van Vectoren, vraagstuk 10
Vectoren, vraagstuk 10 Vectoren, vraagstuk 55
Vectoren, vraagstuk 55 Vraagstukken xref voor de UT
Vraagstukken xref voor de UT De Taylor-reeks van
De Taylor-reeks van De Taylor-reeks van
De Taylor-reeks van Een reeks afsplitsen van
Een reeks afsplitsen van De faculteitsfunctie
De faculteitsfunctie Holomorfie van de functie
Holomorfie van de functie Uitleg artikel algemene relativiteitstheorie: inleiding hoofdstuk D
Uitleg artikel algemene relativiteitstheorie: inleiding hoofdstuk D Relativistische periheliumprecessie, 2e orde benadering
Relativistische periheliumprecessie, 2e orde benadering Waar begint de spaghettificatie?
Waar begint de spaghettificatie? De zwaartekracht van een homogene ronde ster
De zwaartekracht van een homogene ronde ster De integraal van
De integraal van De Witte Dag
De Witte Dag De integraal van
De integraal van De cycloïde
De cycloïde De minimale straal van een holle bol
De minimale straal van een holle bol Een planeettijdreismachine
Een planeettijdreismachine De integralen van
De integralen van Gravitationele rood-/blauwverschuiving
Gravitationele rood-/blauwverschuiving Getijdenkrachten
Getijdenkrachten Zijn wij vroeg of laat?
Zijn wij vroeg of laat? Overzichtspagina wiskunde
Overzichtspagina wiskunde Overzichtspagina natuurkunde
Overzichtspagina natuurkunde Overzichtspagina filosofie
Overzichtspagina filosofie Doneer enkele euro’s
Doneer enkele euro’s Wetenschappelijke boeken te koop
Wetenschappelijke boeken te koop Lezingen
Lezingen