Matrices
Een matrix is in beginsel een rechthoek gevuld met getallen (of eventueel iets complexers zoals functies):
Iedere horizontale reeks noemen we een
rij en iedere verticale reeks een
kolom.
Indien het aantal rijen gelijk is aan het aantal kolommen dan is het een
vierkante matrix.
In plaats van rechte haken mag je ook ronde haken gebruiken (want wat dit punt betreft is er geen eenduidige
conventie, dus doe waar je zin in hebt):
Ieder a’tje in de matrix noemen we een
element
(
vectoren en tensoren hebben componenten,
matrices hebben elementen).
Indien de matrix vierkant is dan vormen de elementen van linksboven naar rechtsonder de
hoofddiagonaal
(ook wel kortweg aangegeven met ‘de diagonaal’):
En de elementen van rechtsboven naar linksonder vormen de
nevendiagonaal:
Wanneer bij een vierkante matrix alle elementen nul zijn behalve die op de hoofddiagonaal dan spreken we van
een
diagonale matrix:
Door rijen en kolommen te verwisselen, dit heet
transponeren of de
transponent nemen,
ontstaat de getransponeerde matrix en dat geven we aan met een hoge index T:
Een matrix die gelijk is aan zijn getransponeerde versie is
symmetrisch en het moge duidelijk zijn dat
dit alleen bij een vierkante matrix kan.
Indien het transponeren van een matrix leidt tot een tekenwisseling van alle elementen dan is de matrix
anti-symmetrisch (en ook dit kan natuurlijk alleen bij een vierkante matrix):
Hieruit volgt dat de elementen op de hoofddiagonaal van een anti-symmetrische matrix altijd nul zijn.
Het vermenigvuldigen van twee matrices gebeurt door paarsgewijs de rijelementen van de eerste matrix te
vermenigvuldigen met de kolomelementen van de tweede matrix en bij elkaar op te tellen:
Ik schrijf even een paar c-elementen uit:
Of in woorden:
- ieder element cij vormt zich door alle elementen van de i-de rij van de eerste matrix paarsgewijs
te vermenigvuldigen met alle elementen van de j-de kolom van de tweede matrix en al die paren bij elkaar op te
tellen.
Klopt, als je dit ‘met de hand’ moet doen dan is een foutje snel gemaakt.
Om matrices met elkaar te kúnnen vermenigvuldigen is het dus wel noodzakelijk dat het aantal kolommen van de
eerste matrix gelijk is aan het aantal rijen van de tweede matrix.
Het goede nieuws daarentegen is dat je aan de rechterkant van een matrix altijd kolommen met nullen toe mag
voegen of aan de onderkant rijen met nullen, op die manier kun je de boel altijd ‘passend’ maken.
Ik ga dit nader onderzoeken door twee 2 × 2 matrices (spreek uit als “twee bij twee matrices”) met elkaar
te vermenigvuldigen:
In vergelijking (11) is het ook eenvoudig in te zien dat matrixvermenigvuldiging niet commutatief is (A maal B is
niet gelijk aan B maal A, al zou dat toevallig wel het geval kunnen zijn).
Ik ga nu in bovenstaande vergelijking bij toerbeurt een rij en/of kolom nul maken:
Meer smaken zijn er niet.
Uit het hierbovenstaande kan ik conclusies gaan trekken:
- kolom maal kolom = kolom (vergelijking (12h)),
- kolom maal rij = vierkant (vergelijking (12g)),
- kolom maal vierkant = vierkant (vergelijking (12b)),
- rij maal kolom = vierkant 1 × 1 (vergelijking (12f)),
- rij maal rij = rij (vergelijking (12e)),
- rij maal vierkant = rij (vergelijking (12a)),
- vierkant maal kolom = kolom (vergelijking (12d)),
- vierkant maal rij = vierkant (vergelijking (12c)),
- vierkant maal vierkant = vierkant (vergelijking (11)),
- vierkant 1 × 1 maal vierkant = rij (vergelijking (12i)),
- vierkant maal vierkant 1 × 1 = kolom (vergelijking (12j)).
Met wat fantasie kan ik de uitkomst van vergelijking (12f) duiden als een getal en als zodanig als het
inwendig product.
Het
inwendig product van twee
vectoren is namelijk een getal:
Door de eerste
vector als een rij te
schrijven in plaats van een kolom lijkt dit inderdaad heel veel op vergelijking (12f):
En hier wordt inderdaad gebruik van gemaakt in de kwantummechanica bij de zogenaamde
braketnotatie:
Dat was even een klein zijstapje.
Vervolgens introduceer ik de
eenheidsmatrix, een diagonale matrix met alleen maar enen op de hoofddiagonaal:
Stel dat ik twee matrices met elkaar vermenigvuldig en dat levert de eenheidsmatrix op:
Dan kan het niet anders dan dat de tweede matrix de
inverse matrix is van de eerste en dit geven we aan
met de hoge index −1:
Door het oplossen van een aantal lineaire vergelijkingen kan ik dus voor een willekeurige matrix de inverse
matrix bepalen, ik begin heel simpel met een 1 × 1 matrix:
Dit levert één lineaire vergelijking op:
Aldus is de inverse matrix van een willekeurige 1 × 1 matrix:
Dit was inderdaad heel gemakkelijk, eigenlijk een beetje flauw.
Voor een 2 × 2 matrix wordt het al een stuk uitdagender, want het aantal vergelijkingen dat ik op moet lossen
neemt
kwadratisch toe met het aantal
rijen/kolommen:
Dit levert vier lineaire vergelijkingen op:
Vergelijking (23a) substitueer ik in (23c) en (23b) in (23d):
Vervolgens substitueer ik vergelijking (24a) in (23a) en (24b) in (23b):
Ik stel:
Aldus is de inverse matrix van een willekeurige 2 × 2 matrix:
Die factor D is de
determinant van de matrix:
Ik ga mijn resultaat even controleren:
En omgekeerd werkt het net zo:
Ik ga ook nog ‘effe’ de inverse matrix bepalen van een 3 × 3 matrix:
Dit levert negen lineaire vergelijkingen op:
Vergelijking (32a) substitueer ik in (32d) en (32g), vergelijking (32b) in (32e) en (32h) en
vergelijking (32c) in (32f) en (32i):
Vervolgens substitueer ik vergelijking (33a) in (33d), (33b) in (33e) en (33c) in (33f):
Ik stel:
Zodat de vergelijkingen (34) tenslotte worden:
Vervolgens substitueer ik vergelijking (36a) in (33d), (36b) in (33e) en (36c) in (33f):
En door tenslotte de vergelijkingen (36) en (37) in (32a/b/c) te substitueren vind ik de laatste
elementen van de inverse matrix:
Aldus is de inverse matrix van een willekeurige 3 × 3 matrix:
Die factor D is wederom de determinant van de matrix:
Ik ga mijn resultaat weer controleren:
Ik werk dit even element voor element apart uit:
Oftewel:
En omgekeerd werkt het net zo:
Zoals ik al zei neemt de complexiteit van het bepalen van de inverse matrix
kwadratisch toe met het aantal rijen/kolommen,
dus aan een 4 × 4 matrix ga ik niet beginnen.
Dit is daarom een goed moment om het over determinanten te gaan hebben.
De determinant van een 2 × 2 matrix is per definitie:
Er zijn meerdere manieren om de determinant van een grotere matrix te bepalen, maar de volgende manier vind ik
het handigst (want die kun je blind toepassen, werkt altijd).
Stel je wilt de determinant bepalen van een 3 × 3 matrix:
Je neemt de elementen van de bovenste rij en geeft ze afwisselend plustekens en mintekens (te beginnen met een
plusteken):
En vervolgens zet je achter ieder element van de bovenste rij de
onderdeterminant.
De onderdeterminant is datgene dat overblijft wanneer je de bovenste rij van de matrix wegsloopt en ook nog
de kolom wegsloopt waar dat specifieke element van de bovenste rij zich in bevindt:
En deze drie onderdeterminanten verwerk je volgens vergelijking (47):
Laten we ook nog de determinant bepalen van een 4 × 4 matrix:
Je neemt weer de elementen van de bovenste rij en geeft ze afwisselend plustekens en mintekens (te beginnen
met een plusteken):
En vervolgens zet je achter ieder element van de bovenste rij de onderdeterminant.
De onderdeterminant is datgene dat overblijft wanneer je de bovenste rij van de matrix wegsloopt en ook nog
de kolom wegsloopt waar dat specifieke element van de bovenste rij zich in bevindt:
En deze vier onderdeterminanten verwerk je volgens vergelijking (51) (of je gaat iedere onderdeterminant
nogmaals in kleinere mootjes hakken, maar dat hebben we net al gedaan dus laten we gelijk van dat
resultaat gebruik maken):
Merk op dat het aantal termen van de determinant toeneemt met de
faculteit van het aantal rijen/kolommen.
Bij een 2 × 2 matrix heeft de determinant 2! = 2 termen, bij een 3 × 3 matrix heeft de determinant 3! = 6 termen
en bij een 4 × 4 matrix heeft de determinant al 4! = 24 termen!
Met deze nieuw vergaarde kennis pak ik vergelijking (39b) er weer bij:
Al die elementen kan ik ook opschrijven als onderdeterminanten:
Kijk, nu komt er licht aan het eind van de tunnel.
Ik pak vergelijking (27b) er ook nog even bij:
Ook dit kan ik opschrijven in termen van onderdeterminanten:
Voor een willekeurige matrix kan ik ieder element van de inverse matrix dus rechtstreeks opschrijven als volgt:
Ik heb bij het eerste a’tje een hoge index −1 gezet om aan te geven dat dat een element is van de inverse
matrix (het andere a’tje is een element van de oorspronkelijke matrix).
Wat kun je nu eigenlijk met matrices?
Ik zal wat voorbeelden geven.
Indien ik een stel coördinaten heb, bijvoorbeeld een punt P met coördinaten x, y en z, en ik arrangeer die in een
matrix van één kolom dan kan ik die coördinaten verplaatsen door vermenigvuldiging met een andere matrix als volgt:
De matrix waarmee ik de coördinaten transformeer heet, je raadt het al, de
transformatiematrix.
Door vermenigvuldiging met de eenheidsmatrix blijven de coördinaten ongewijzigd en blijft het punt P op zijn plaats:
Maar op deze manier leg ik het punt P tweemaal zo ver weg (verder van de oorsprong):
En zo haal ik het punt P tweemaal zo dichtbij (dichter bij de oorsprong):
In de bovenstaande drie voorbeelden had ik de matrix met de coördinaten ook simpelweg met een getal kunnen
vermenigvuldigen (met respectievelijk 1, 2 en 0.5) om hetzelfde resultaat te krijgen.
Hier wordt uitgebreid gebruik van gemaakt binnen de kwantummechanica.
Dus, stel ik heb de volgende situatie (met k een of ander getal):
Wanneer dit optreedt dan noemen we de matrix met de coördinaten de
eigenvector:
Het getal k heet de
eigenwaarde.
Wanneer je je in kwantummechanica gaat verdiepen dan krijg je hier gegarandeerd mee te maken.
Een ander bijzonder geval van een transformatiematrix is de
rotatiematrix, hiermee kan ik een punt
over een bepaalde hoek roteren.
Op deze manier roteer ik een hoek α tegen de wijzers van de klok in (voor de duidelijkheid even in twee
dimensies):
Door de hoek α negatief te maken, of de inverse matrix te nemen, dat komt op hetzelfde neer, roteer ik
met de wijzers van de klok mee:
Een transformatiematrix is natuurlijk ook bij uitstek geschikt om coördinatentransformaties mee uit te voeren.
De matrices van de vergelijkingen (59) tot en met (66) zijn allemaal transformatiematrices:
Door een dergelijke matrix los te laten op een willekeurige
vector v verplaats ik die
vector, maar dat kan ik ook zien als de overgang
naar een ander coördinatenstelsel:
De inverse transformatie gebeurt dan uiteraard middels de inverse transformatiematrix:


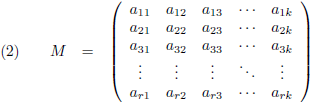
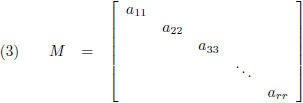
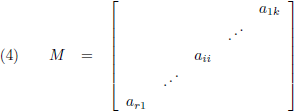
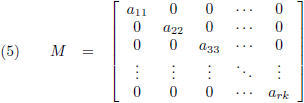

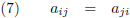
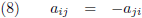
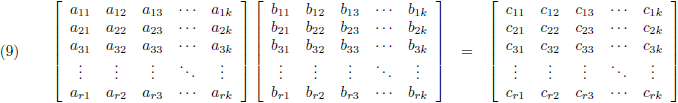
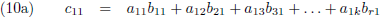
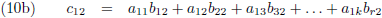
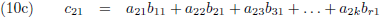
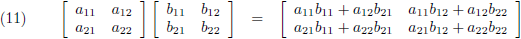
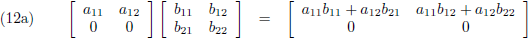
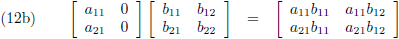
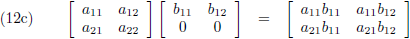
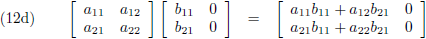
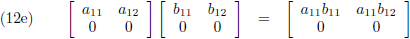
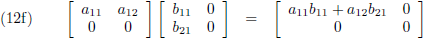
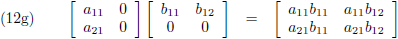
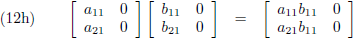
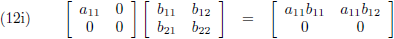
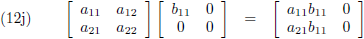
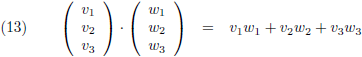
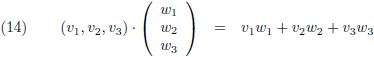
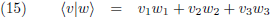
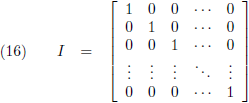
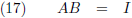
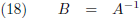
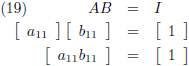
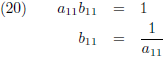
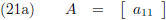
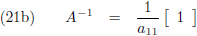
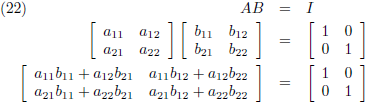
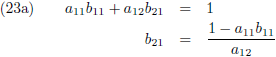
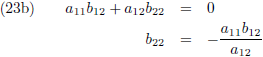
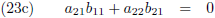
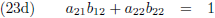
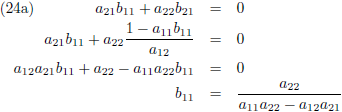
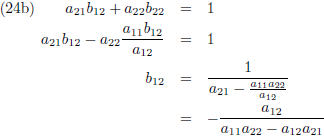
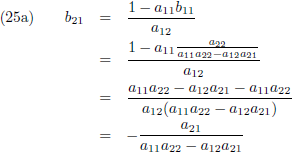
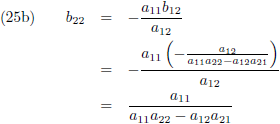

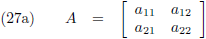
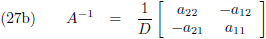
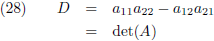
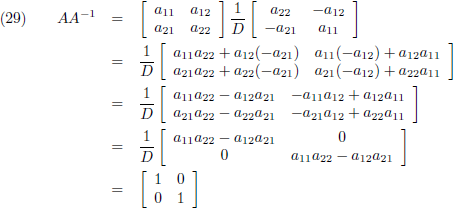
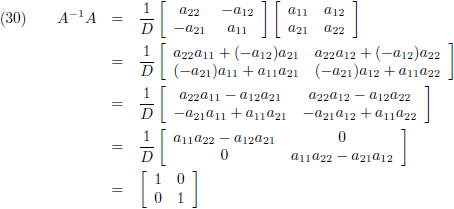
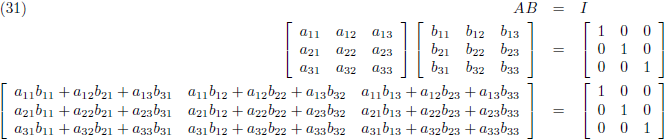
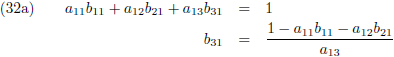
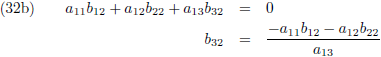
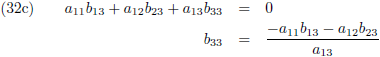
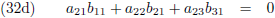
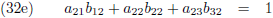
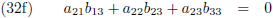
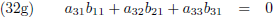
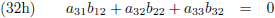
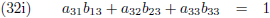
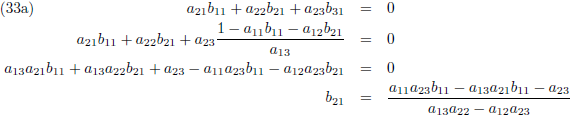
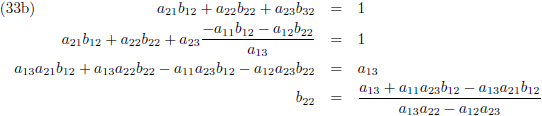
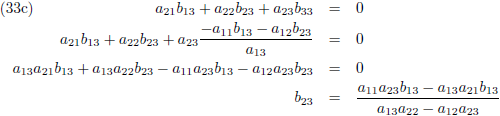
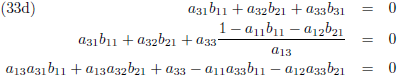
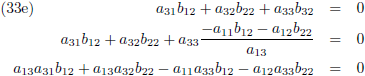
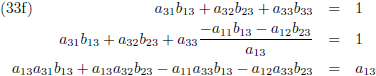
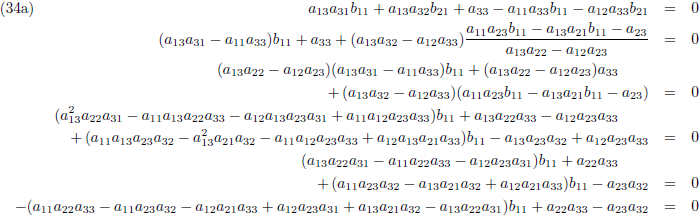
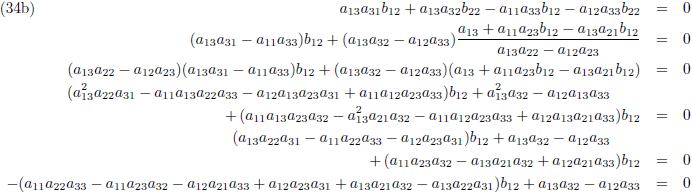
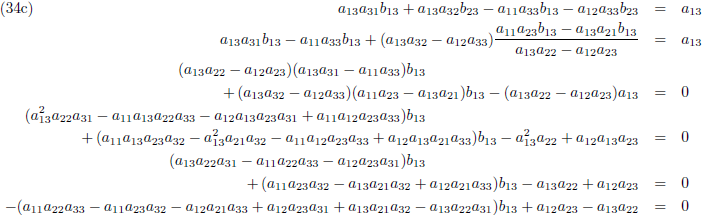
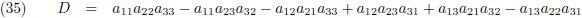
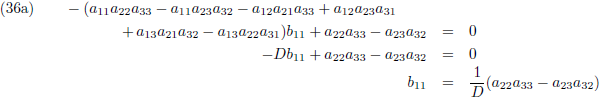
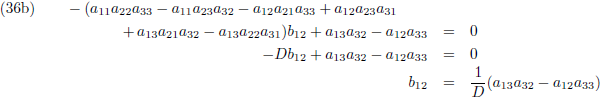
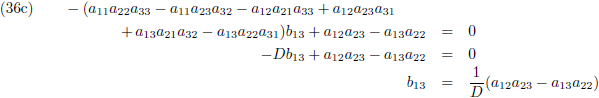
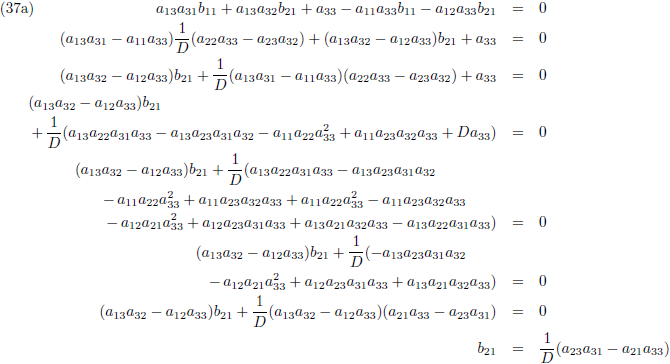
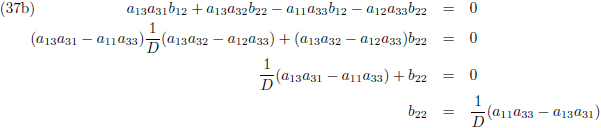
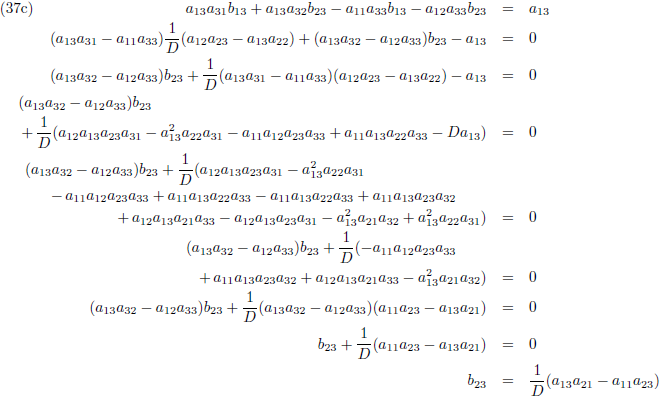
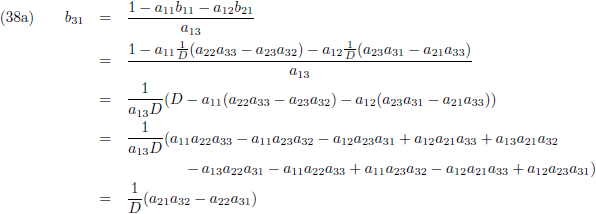
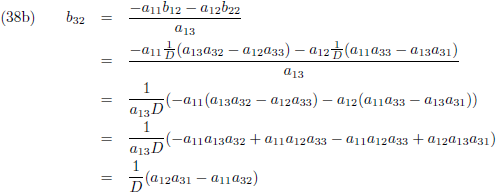
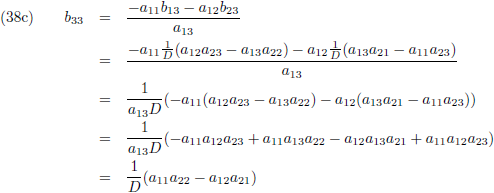
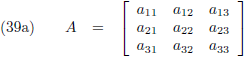
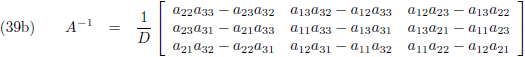
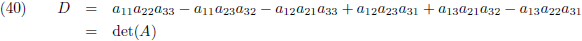
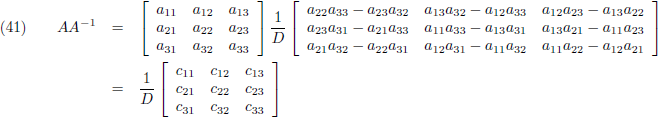
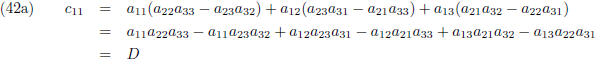
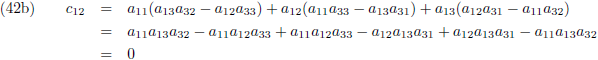
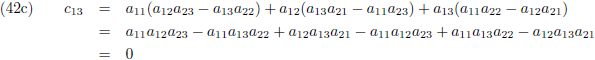
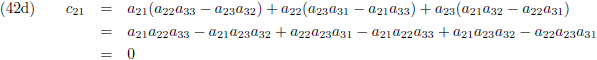
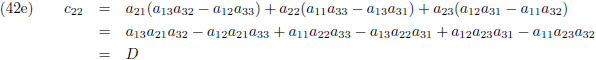
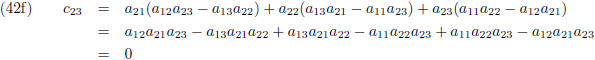
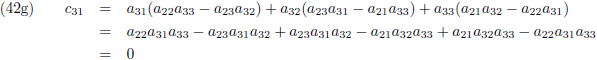
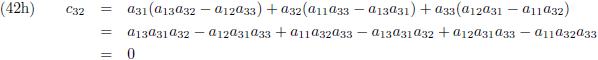
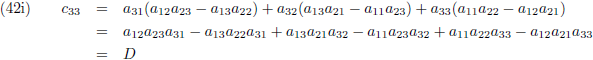
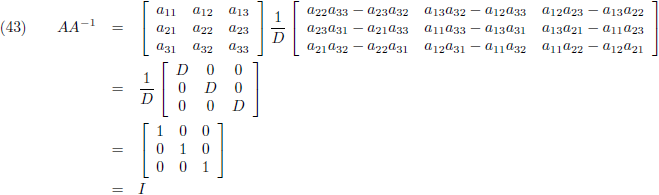

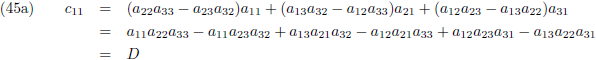
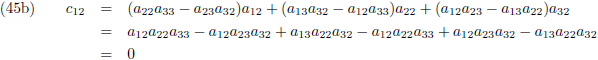
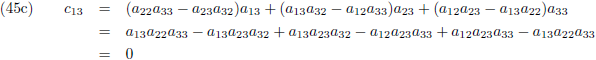
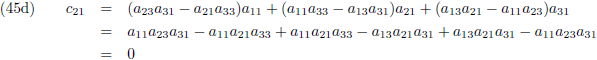
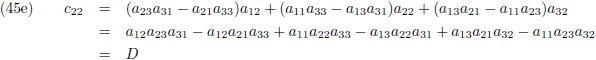
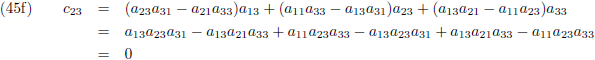
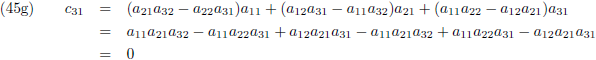
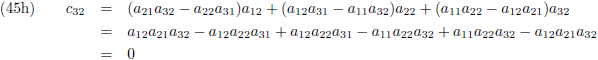
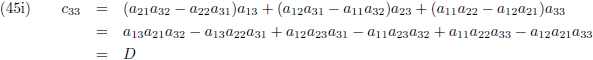
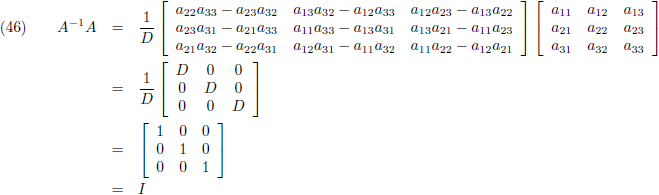
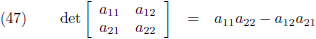

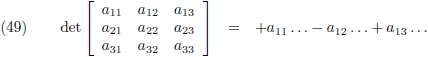
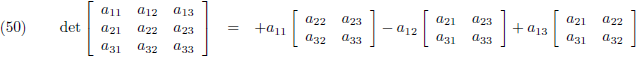
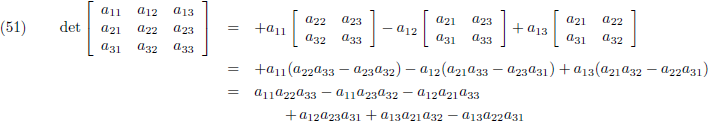
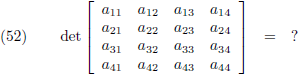
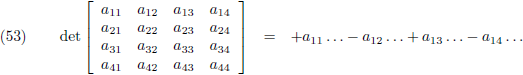
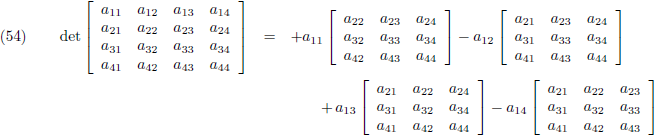

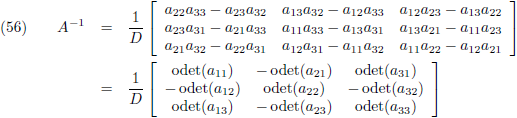
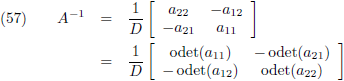
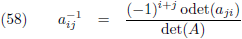
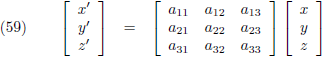
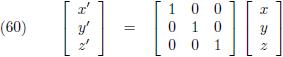
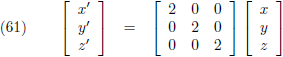
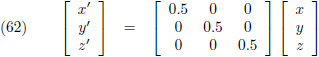
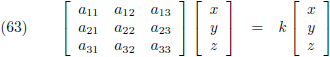
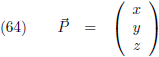
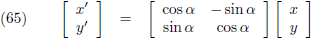
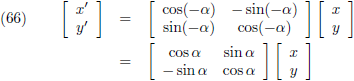
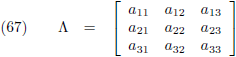
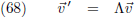
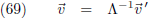
 De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integralen van
De integralen van Vectoren, vraagstuk 20
Vectoren, vraagstuk 20 Vectoren, vraagstuk 58
Vectoren, vraagstuk 58 Covariante - en contravariante componenten van een vector
Covariante - en contravariante componenten van een vector Tabel met Taylor-reeksen
Tabel met Taylor-reeksen De Taylor-reeks van
De Taylor-reeks van De stelling van Gauss
De stelling van Gauss Relativiteitstheorie basic, hoofdstuk 3: het balletje
Relativiteitstheorie basic, hoofdstuk 3: het balletje Uitleg artikel algemene relativiteitstheorie: paragraaf 18
Uitleg artikel algemene relativiteitstheorie: paragraaf 18 Binnen een mensenleven het heelal doorkruisen
Binnen een mensenleven het heelal doorkruisen De uitdijing van het heelal
De uitdijing van het heelal Analyse van een model voor de dichtheid van de Zon
Analyse van een model voor de dichtheid van de Zon Vraagstukken algemene natuurkunde
Vraagstukken algemene natuurkunde De illusie dat ik goed kan autorijden
De illusie dat ik goed kan autorijden De reis naar de werkelijkheid van Albert Einstein
De reis naar de werkelijkheid van Albert Einstein Ruimte maken voor je geluid
Ruimte maken voor je geluid De Natuur spreekt: The Rainforest/Het Regenwoud
De Natuur spreekt: The Rainforest/Het Regenwoud Natuurkundeclub Gℏc
Natuurkundeclub Gℏc LaTeX: wiskundige ruimtes
LaTeX: wiskundige ruimtes Kalender van de jaren 0171 − 0180 met weekdagen
Kalender van de jaren 0171 − 0180 met weekdagen Voorbeelden van E = mc2
Voorbeelden van E = mc2 De pijn die je voelt wanneer je in een zwart gat valt
De pijn die je voelt wanneer je in een zwart gat valt De versnelling van een baksteen die in een zwart gat valt
De versnelling van een baksteen die in een zwart gat valt De snelheid van een baksteen die in een zwart gat valt
De snelheid van een baksteen die in een zwart gat valt De Euler-Lagrange-vergelijking
De Euler-Lagrange-vergelijking De baan van een baksteen bij een zwart gat
De baan van een baksteen bij een zwart gat De Taylor-reeks van f (x) = tan (ax)
De Taylor-reeks van f (x) = tan (ax) De integralen van f (x) = sin2 x/(1 + a cos x)2
De integralen van f (x) = sin2 x/(1 + a cos x)2 De integraal van f (x) = 1/(x2 (ax2 + bx + c))
De integraal van f (x) = 1/(x2 (ax2 + bx + c)) De invaltijd van een baksteen die in een zwart gat valt
De invaltijd van een baksteen die in een zwart gat valt Naar de overzichtspagina wiskunde
Naar de overzichtspagina wiskunde Naar de overzichtspagina natuurkunde
Naar de overzichtspagina natuurkunde Naar de overzichtspagina filosofie
Naar de overzichtspagina filosofie Doneer enkele euro’s
Doneer enkele euro’s Wetenschappelijke boeken te koop
Wetenschappelijke boeken te koop Lezingen
Lezingen