Error 404: Not Found

Oeps! En toen was je ineens waar je niet wezen wilde!
Maak je keuze in het menu om vrolijk verder te gaan op deze website.
Excuses voor het ongemak!
Maak je keuze in het menu om vrolijk verder te gaan op deze website.
Excuses voor het ongemak!
 De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integraal van
De integraal van De integralen van
De integralen van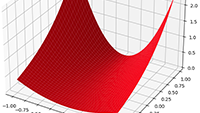 Vectoren, vraagstuk 58
Vectoren, vraagstuk 58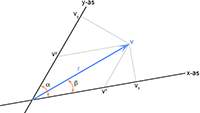 Covariante - en contravariante componenten van een vector
Covariante - en contravariante componenten van een vector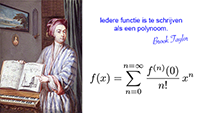 Tabel met Taylor-reeksen
Tabel met Taylor-reeksen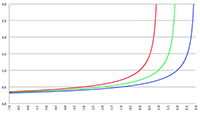 De Taylor-reeks van
De Taylor-reeks van De stelling van Gauss
De stelling van Gauss Relativiteitstheorie basic, hoofdstuk 3: het balletje
Relativiteitstheorie basic, hoofdstuk 3: het balletje Uitleg artikel algemene relativiteitstheorie: paragraaf 18
Uitleg artikel algemene relativiteitstheorie: paragraaf 18 Binnen een mensenleven het heelal doorkruisen
Binnen een mensenleven het heelal doorkruisen De uitdijing van het heelal
De uitdijing van het heelal Analyse van een model voor de dichtheid van de Zon
Analyse van een model voor de dichtheid van de Zon Vraagstukken algemene natuurkunde
Vraagstukken algemene natuurkunde De illusie dat ik goed kan autorijden
De illusie dat ik goed kan autorijden De reis naar de werkelijkheid van Albert Einstein
De reis naar de werkelijkheid van Albert Einstein Ruimte maken voor je geluid
Ruimte maken voor je geluid De Natuur spreekt: The Rainforest/Het Regenwoud
De Natuur spreekt: The Rainforest/Het Regenwoud Natuurkundeclub Gℏc
Natuurkundeclub Gℏc LaTeX: wiskundige ruimtes
LaTeX: wiskundige ruimtes Kalender van de jaren 0171 − 0180 met weekdagen
Kalender van de jaren 0171 − 0180 met weekdagen Kalender van de jaren 0551 − 0560 met weekdagen
Kalender van de jaren 0551 − 0560 met weekdagen Voorbeelden van E = mc2
Voorbeelden van E = mc2 De pijn die je voelt wanneer je in een zwart gat valt
De pijn die je voelt wanneer je in een zwart gat valt De versnelling van een baksteen die in een zwart gat valt
De versnelling van een baksteen die in een zwart gat valt De snelheid van een baksteen die in een zwart gat valt
De snelheid van een baksteen die in een zwart gat valt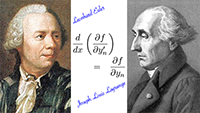 De Euler-Lagrange-vergelijking
De Euler-Lagrange-vergelijking De baan van een baksteen bij een zwart gat
De baan van een baksteen bij een zwart gat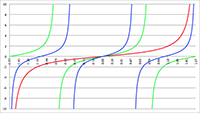 De Taylor-reeks van f (x) = tan (ax)
De Taylor-reeks van f (x) = tan (ax)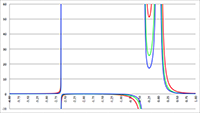 De integraal van f (x) = 1/(x2 (ax2 + bx + c))
De integraal van f (x) = 1/(x2 (ax2 + bx + c)) De invaltijd van een baksteen die in een zwart gat valt
De invaltijd van een baksteen die in een zwart gat valt Naar de overzichtspagina wiskunde
Naar de overzichtspagina wiskunde Naar de overzichtspagina natuurkunde
Naar de overzichtspagina natuurkunde Naar de overzichtspagina filosofie
Naar de overzichtspagina filosofie Doneer enkele euro’s
Doneer enkele euro’s Wetenschappelijke boeken te koop
Wetenschappelijke boeken te koop Lezingen
Lezingen